Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server su Linux
SQL Server su Linux
Questo articolo illustra la configurazione della memoria per SQL Server in Linux, inclusi mssql-conf limiti di memoria, impostazioni del gruppo di controllo (cgroup), esempi di memoria del contenitore Docker e considerazioni sullo scambio dello spazio.
Note
Per consigli su archiviazione, kernel, CPU e rete, vedere Procedure consigliate per le prestazioni: Archiviazione, kernel, CPU e rete per SQL Server in Linux.
Impostare un limite di memoria usando mssql-conf
Per assicurarsi che sia disponibile memoria fisica sufficiente per il sistema operativo Linux, il processo di SQL Server usa solo l'80% della RAM fisica per impostazione predefinita. Per alcuni sistemi con grandi quantità di RAM fisica, il 20% potrebbe essere un numero significativo. Ad esempio, in un sistema con 1 TB di RAM, l'impostazione predefinita lascia circa 200 GB di RAM inutilizzata. In questo caso, potrebbe essere necessario configurare il limite di memoria su un valore superiore.
È possibile modificare questo valore usando lo mssql-conf strumento o la MSSQL_MEMORY_LIMIT_MB variabile di ambiente. Per altre informazioni, vedere l'impostazione memory.memorylimitmb che controlla la memoria visibile a SQL Server (in unità di MB). Per indicazioni dettagliate sul dimensionamento, vedere Linee guida per l'impostazione dei limiti di memoria in Linux e nei contenitori.
Supporto del gruppo di controllo (cgroup) v2
SQL Server rileva e rispetta i vincoli del gruppo di controllo (cgroup) v2, a partire da SQL Server 2025 (17.x) e SQL Server 2022 (16.x) Aggiornamento cumulativo (CU) 20. Questi vincoli forniscono un controllo granulare nel kernel Linux sulle risorse cpu e memoria e migliorano l'isolamento delle risorse negli ambienti Docker, Kubernetes e OpenShift.
Nelle versioni precedenti, le distribuzioni in contenitori nei cluster Kubernetes (ad esempio, servizio Azure Kubernetes v1.25+) potrebbero riscontrare errori di memoria insufficiente perché SQL Server non imponeva limiti di memoria definiti nelle specifiche del contenitore. Il supporto per cgroup v2 risolve questo problema.
Controllare la versione di cgroup
stat -fc %T /sys/fs/cgroup
I risultati sono i seguenti:
| Result | Descrizione |
|---|---|
cgroup2fs |
Viene utilizzato cgroup v2 |
cgroup |
Usare cgroup v1 |
Passare a cgroup v2
Il percorso più semplice consiste nella scelta di una distribuzione che supporta cgroup v2 predefinita.
Se è necessario passare manualmente, aggiungere il parametro seguente alla configurazione GRUB:
systemd.unified_cgroup_hierarchy=1
Aggiornare quindi GRUB. Ad esempio, in Ubuntu eseguire:
sudo update-grub
Su Red Hat Enterprise Linux, eseguire:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Creazione di report sui limiti della CPU con cgroup v2
Quando si configurano i limiti della CPU usando cgroup v2, SQL Server non mostra il numero di core CPU configurato nel log degli errori. Continua invece a segnalare il numero totale di CPU host.
Per allineare SQL Server scheduler e piani di query (ad esempio, decisioni di parallelismo) con il numero di CPU previsto definito in cgroup v2, applicare la configurazione seguente.
Configurare l'affinità del processore
Imposta in modo esplicito l'affinità del processore di SQL Server per corrispondere alla quota di esecuzione del cgroup. Nell'esempio seguente la quota di cgroup è di quattro CPU in un host a otto core:
ALTER SERVER CONFIGURATION
SET PROCESS AFFINITY CPU = 0 TO 3;
Questa configurazione garantisce che SQL Server crei pianificatori solo per il numero desiderato di CPU. Per ulteriori informazioni, vedi ALTER SERVER CONFIGURATION e Utilizzare PROCESS AFFINITY per Node e/o CPU.
Abilitare il flag di traccia 8002 (scelta consigliata)
Abilitare il flag di traccia 8002 per usare l'affinità soft a livello di SQLPAL:
sudo /opt/mssql/bin/mssql-conf traceflag 8002 on
Per impostazione predefinita, le utilità di pianificazione sono associate a CPU specifiche definite nella maschera di affinità. Il flag di traccia 8002 consente agli schedulatori di spostarsi tra CPU, migliorando in genere le prestazioni pur rispettando i vincoli di affinità e Cgroup. Per ulteriori informazioni, vedere DBCC TRACEON - Flag di monitoraggio.
Riavviare SQL Server dopo aver abilitato il flag di traccia.
Comportamento previsto
Dopo il riavvio:
SQL Server crea solo il numero di utilità di pianificazione definite dall'impostazione di affinità, ad esempio quattro utilità di pianificazione.
Il kernel Linux continua a applicare la quota di esecuzione della CPU cgroup v2.
Le decisioni relative all'ottimizzazione delle query e al parallelismo si basano sul numero di CPU previsto, anziché sulle CPU host totali.
Note
Il log degli errori SQL Server potrebbe continuare a visualizzare il numero totale di CPU host. Questo comportamento di registrazione e visualizzazione non influisce sull'utilizzo effettivo della CPU, sulla creazione dello schedulatore o sull'applicazione delle restrizioni CPU da parte di cgroup v2 o dall'affinità del processore.
Per ulteriori informazioni, vedi le seguenti risorse:
- Avvio rapido: Distribuire un contenitore di SQL Server in Linux nel servizio Kubernetes usando grafici Helm
- Gruppo di controllo v2 (documentazione del kernel Linux)
Linee guida per l'impostazione dei limiti di memoria in Linux e nei contenitori
SQL Server in Linux dispone di più controlli di memoria che operano a livelli diversi. La tabella e il diagramma seguenti illustrano come ogni livello restringe la memoria disponibile, dalla RAM host fino al pool di buffer.
| livello | Impostato da | Descrizione |
|---|---|---|
| Host | Configurazione hardware/macchina virtuale | RAM fisica nel server o nella macchina virtuale.Physical RAM on the server or virtual machine (VM). |
limite di cgroup (docker run --memory, systemd, o manuale) |
runtime del container, systemd slice o configurazione manuale cgroup |
Limite massimo imposto dal kernel (memory.max) per tutti i processi in cgroup. Opzionale su Linux bare metal. |
processo di SQL Server (memorylimitmb / MSSQL_MEMORY_LIMIT_MB) |
mssql-conf o variabile di ambiente |
Memoria totale in tutti i componenti SQL Server. Deve essere inferiore al cgroup limite (se presente) o alla memoria host. |
Pool di buffer (max_server_memory) |
sp_configure |
Cache di pagine di dati da 8 KB. Deve essere inferiore a memorylimitmb. |
| Sala testata | Calcolato (differenza tra i limiti) | La differenza tra il limite cgroup (o la memoria host) e memorylimitmb, riservata all'overhead del sistema operativo e ai processi ausiliari. |
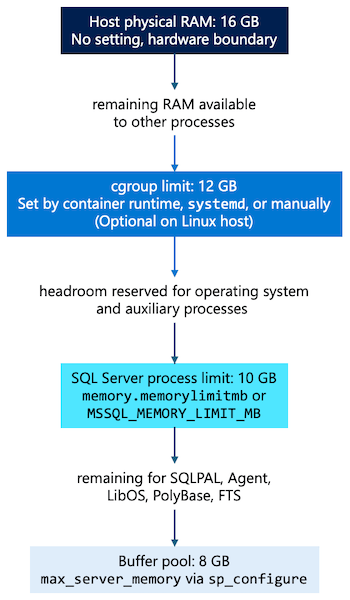
Quando si impostano i limiti di memoria per SQL Server in Linux, prendere in considerazione le linee guida seguenti:
Nelle distribuzioni di contenitori usare
cgroupper limitare la memoria complessiva disponibile per il contenitore. Questa impostazione stabilisce il limite superiore per tutti i processi all'interno del contenitore.Il limite di memoria (impostato da
memorylimitmbo variabileMSSQL_MEMORY_LIMIT_MBdi ambiente) controlla la memoria totale che SQL Server in Linux può allocare in tutti i relativi componenti, ad esempio il pool di buffer, SQLPAL, SQL Server Agent, LibOS, PolyBase, Full-Text Search e qualsiasi altro processo caricato in SQL Server in Linux.La
MSSQL_MEMORY_LIMIT_MBvariabile di ambiente ha la precedenza sumemorylimitmbdefinita inmssql.conf.memorylimitmbnon può superare la memoria fisica effettiva del sistema host.Impostare
memorylimitmbun valore inferiore alla memoria del sistema host e alcgrouplimite (se presente), per assicurarsi che sia disponibile memoria fisica sufficiente per il sistema operativo Linux. Se non si impostamemorylimitmbin modo esplicito , SQL Server usa l'80% del valore minore tra la memoria totale di sistema e ilcgrouplimite (se presente).L'opzione di configurazione del server max_server_memory limita solo le dimensioni del pool di buffer di SQL Server e non regola l'utilizzo complessivo della memoria per SQL Server in Linux. Impostare sempre questo valore a un livello inferiore a
memorylimitmbper garantire che rimanga memoria sufficiente per gli altri componenti descritti nel punto elenco precedente.
Margine tra SQL Server e i limiti di memoria del contenitore
Quando si esegue SQL Server in un contenitore con un limite di memoria configurato (ad esempio, l'impostazione cgroupmemory.max), mantenere un margine di memoria tra memory.memorylimitmb e il limite di memoria del contenitore. Questo margine di risorse copre l'overhead del sistema operativo e i processi ausiliari all'interno del container.
Per la maggior parte delle distribuzioni, riservare tra il 10 e il 20% della memoria del contenitore per il sistema operativo e i processi non SQL Server e impostare
memory.memorylimitmbal di sotto della capacità rimanente.Per configurazioni di memoria di grandi dimensioni, un buffer basato su percentuale può riservare più memoria del necessario. Ad esempio, il 10% di un contenitore da 256 GB è di circa 25 GB, che è ragionevole per il sovraccarico del sistema operativo. Tuttavia, il 10% di un contenitore da 512 GB è di circa 51 GB, probabilmente più che il sistema operativo richiede. In questi casi, usare invece un buffer fisso, ridimensionato in modo appropriato per il carico di lavoro e il sovraccarico del sistema operativo e allocare il resto a SQL Server.
Modificare il buffer in base alle caratteristiche del carico di lavoro, ad altri servizi in esecuzione nel contenitore e alla configurazione dell'host.
Note
Non esiste un unico valore di headroom consigliato valido per tutti gli ambienti. Convalidare le impostazioni di memoria tramite test per garantire la stabilità del sistema sotto il carico di picco.
Evitare di configurare limiti di memoria superiori alla memoria disponibile
Non configurare memory.memorylimitmb con un valore di memoria superiore alla memoria fisica disponibile sull'host o al limite di memoria imposto dal contenitore. In questo caso, SQL Server potrebbe utilizzare in modo aggressivo la memoria, lasciando capacità insufficiente per il sistema operativo e i processi di supporto. Questa configurazione può comportare:
- Aumento della pressione della memoria.
- Riduzione della stabilità del sistema e interruzioni impreviste del servizio.
- La terminazione del processo
sqlservrda parte del sistema operativo a causa di condizioni di memoria esaurita (OOM).
Configurare i limiti di memoria di SQL Server al di sotto della memoria effettivamente disponibile per l'host o il contenitore e lasciare un margine di memoria adeguato per il sistema operativo e i servizi di runtime.
Esempi di configurazione della memoria Docker
L'opzione docker run --memory imposta il cgroup limite di memoria per il contenitore. Questo limite è il limite rigido imposto dal kernel per tutti i processi nel contenitore.
MSSQL_MEMORY_LIMIT_MB(o memory.memorylimitmb) controlla la quantità di memoria SQL Server utilizzabile. Come descritto nelle linee guida precedenti, impostare sempre MSSQL_MEMORY_LIMIT_MB a un valore inferiore al limite di memoria del contenitore per lasciare un margine al sistema operativo e ai processi ausiliari.
Gli esempi seguenti usano un host con 16 GB di RAM. Modifica i valori in base al tuo ambiente.
Non consigliato: nessun limite di memoria del contenitore
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=14336" \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Senza --memory, il contenitore non ha alcun cgroup limite massimo.
MSSQL_MEMORY_LIMIT_MB limita SQL Server, ma altri processi all'interno del contenitore possono comunque consumare memoria dell'host senza limiti.
Non consigliato: limite di memoria uguale al limite di memoria di SQL Server
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=12288" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Entrambi i limiti sono impostati su 12 GB (--memory 12g = 12.288 MB). Non rimane alcun margine per l'overhead del sistema operativo o per i processi ausiliari, il che può portare a terminazioni OOM.
Non consigliato: il limite di memoria di SQL Server supera il limite del container
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=14336" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
MSSQL_MEMORY_LIMIT_MB (14 GB) supera il limite del contenitore (12 GB). Questo scenario comporta le condizioni di OOM descritte in Evitare di configurare limiti di memoria superiori alla memoria disponibile.
Consigliato: limite del container con margine per il sistema operativo
docker run -e "ACCEPT_EULA=Y" -e "MSSQL_SA_PASSWORD=<password>" \
-e "MSSQL_MEMORY_LIMIT_MB=10240" \
--memory 12g \
-p 1433:1433 \
-d mcr.microsoft.com/mssql/server:2022-latest
Il contenitore è limitato a 12 GB (--memory 12g) e SQL Server è configurato per l'uso fino a 10 GB (MSSQL_MEMORY_LIMIT_MB=10240). I restanti 2 GB (circa il 17%) forniscono un margine per il sistema operativo e altri processi.
Considerazioni sullo spazio di scambio
Quando si esegue SQL Server in un contenitore, abilitare lo spazio di scambio a livello di host per proteggere il sistema operativo e i processi non SQL Server. Tuttavia, configurare SQL Server per operare entro i limiti di memoria configurati e non basarsi sullo scambio durante il normale funzionamento.
Seguire le linee guida per il limite di memoria per assicurarsi che SQL Server funzioni entro la memoria fisica o il limite di memoria applicabile
cgroup.Se lo scambio è abilitato, considerarlo come una rete di sicurezza per una pressione di memoria temporanea sull'host, non come capacità per carichi di lavoro con stato stabile SQL Server.
Importante
Le prestazioni di SQL Server possono peggiorare significativamente se la pressione sulla memoria provoca lo swapping. Il dimensionamento corretto della memoria è il meccanismo principale per prevenire gli errori correlati alla memoria.